A few weeks ago, I attended the International Society for Music Information Retrieval (ISMIR) 2020 Conference, which was held online in the format of a virtual conference. In this blog post, I write about few papers from the conference and give a brief summary of what I found interesting related to my research interests: lyrics transcription and alignment, vocal extraction, and singing voice.
Multilingual Lyrics-to-audio Alignment
Andrea Vaglio, Romain Hennequin, Manuel Moussallam, Gael Richard, Florence d’Alché-Buc
Summary:
This paper presents a novel scheme for audio-to-lyrics alignment in a multilingual setting using BiLSTMs trained on CTC loss and phonemes as the intermediate representation for lyrics.
Pros:
- One of the first and most successful multilingual lyrics alignment works.
- Evaluation and training on public datasets.
- New subsets of the DALI dataset are released.
- The system works on languages with limited resources.
Cons:
- The authors evaluate on a set with automatically aligned lyrics. Even though the authors mentioned in Q&A sessions that they think these annotations are of good quality by inspection, the word boundaries should be manually annotated for evaluation, as the precision of the currently best alignment systems is around 100ms, it would be difficult to judge annotations by inspection.
A Deep Learning Based Analysis-synthesis Framework for Unison Singing
Pritish Chandna, Helena Cuesta, Emilia Gomez
Summary:
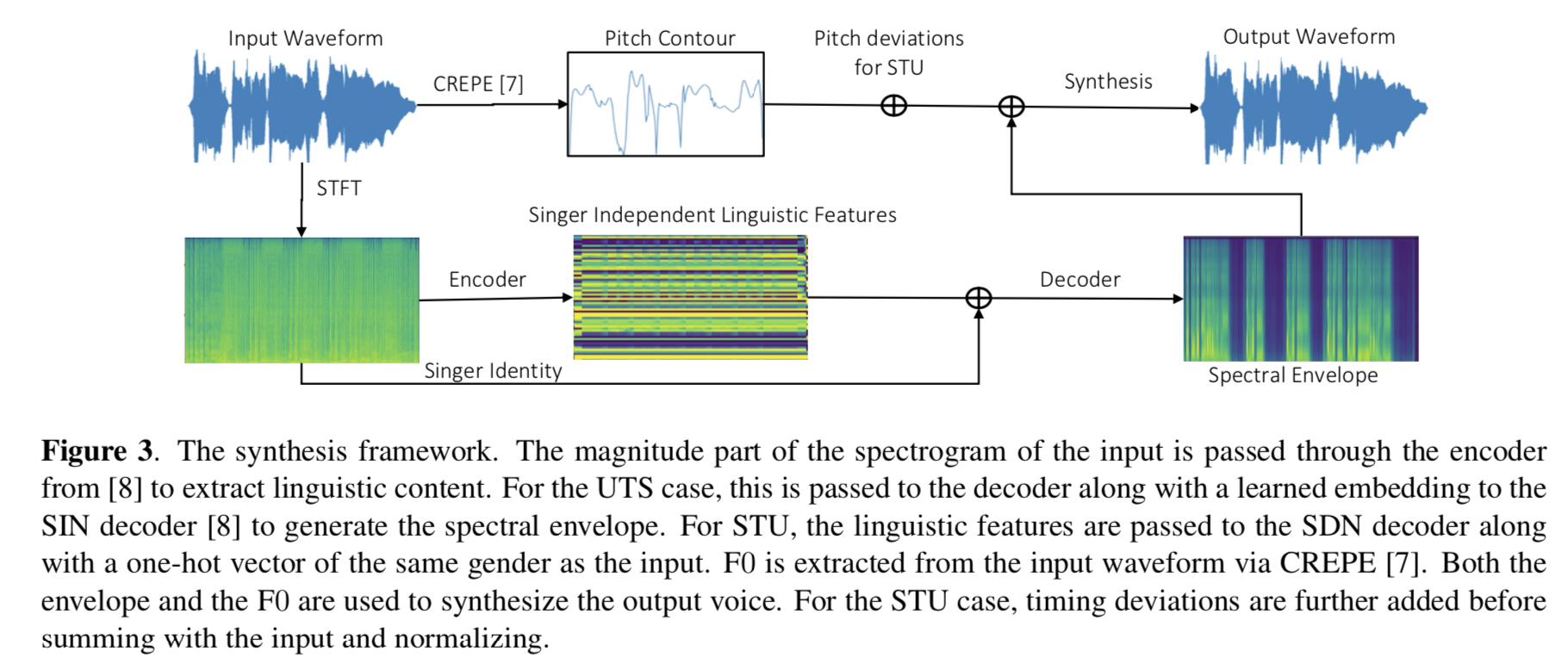
This study applies an extensive computational analysis on choir recordings from the Soprano-Tenor-Alto-Bass (SATB) approach. Moreover, the authors use a novel approach for the retrieval of separate vocal tracks from a mixture of a choir through singing voice synthesis. The authors use singer identity and singer independent linguistic embeddings encoded via neural networks and use this representation for the synthesis. The quality of synthesis is reported through subjective listening tests. Some audio examples are also provided at the following link.
Pros:
- One of the first and few studies on a research topic that has been rarely tackled upon within the MIR community, which is choir singing.
- Reproducibility; open-source datasets for analysis and evaluation, online demo, and code are made publicly available. Something we are used (and appreciate) to see from the works of MTG.
- The online audio examples are convincing by inspection. I anticipate that they would function well for further singing analysis.
Cons:
- I guess objective evaluation metrics are necessary at some point for a more scientific comparison with already existing or future systems.
Content Based Singing Voice Source Separation via Strong Conditioning Using Aligned Phonemes
Gabriel Meseguer Brocal, Geoffroy Peeters
Summary:
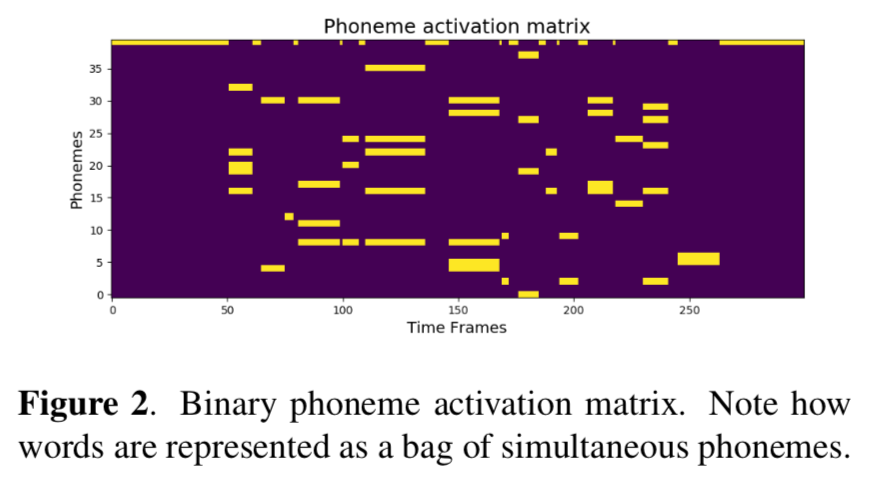
Here is another paper that applies text informed music source separation. Instead of following the naive approach of feature concatenation, the authors have tried multiple ways to incorporate the phonetic information from input lyrics. The words in lyrics are decomposed into their phonetic representations via a pronunciation dictionary. For each word aligned with the audio signal, a global phoneme activation matrix is created on the word-level (see figure). For conditioning the network, this phoneme matrix is embedded in the “Feature-wise Linear Modulation” layers in the C-U-Net architecture the authors employ. Even though the improvement is marginal compared to the unconditioned network, the idea is novel and promising to be investigated more extensively.
Pros:
- A new multitrack dataset for music source separation with aligned lyrics. We always love new annotated data!
- A novel approach to condition text for source separation. There is definitely room for improvement.
- High quality of the paper presentation
Cons:
- Even though the authors report statistical significance, the improvement is still marginal.
- There should be better ways to incorporate phonetic information. In this paper’s approach, the phonemes are not extracted at the frame-level, but at the word-level. Further improvement might be possible if phonemes were aligned with the audio signal on frame-level.
- Also, the phonetic information is represented as word-level global binary activation matrices. Perhaps it would lead to better results if phonetic information was encoded as a probability distribution. This would circumvent the need for lyrics as the input for separation.
Exploring Aligned Lyrics-informed Singing Voice Separation
Chang-Bin Jeon, Hyeong-Seok Choi, Kyogu Lee
Summary:
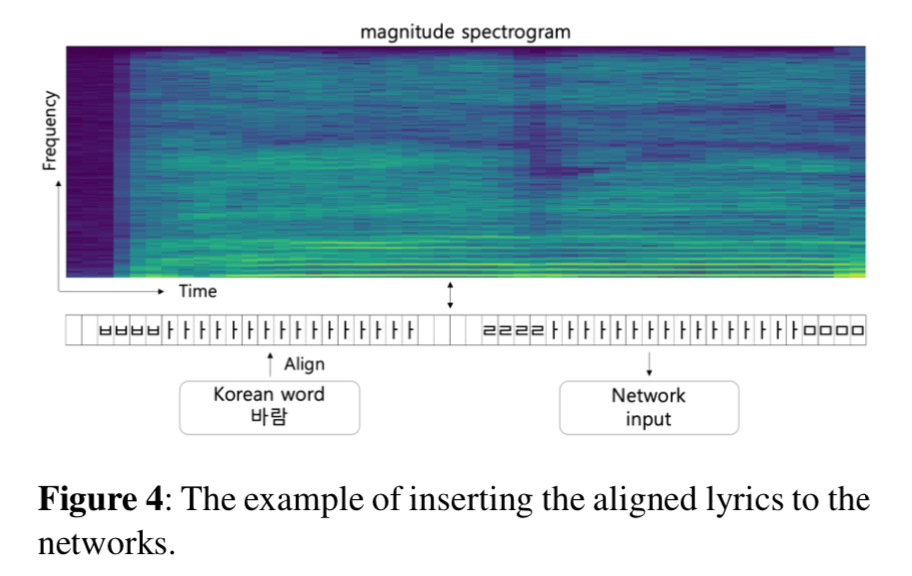
This paper proposes to use phonetic information for source separation and investigates if it does improve the performance. It has lots of similarities with the works by Kilian Schulze-Forster. The phonetic features are extracted from lyrics text only.
Pros:
- The authors propose two methods to incorporate phonetic information into vocal source separation: Local conditioning and feature concatenation.
- I do think that incorporating phonetic information for source separation should work and is a nice idea.
Cons:
- Private dataset! I know it is extremely difficult to find well-curated public datasets for MIR tasks, however, there are some datasets for source separation that people have been using. I would expect to see at least one public dataset in the evaluation. (Notice to peer-reviewers!)
- The work is not extremely different comparing to Kilian’s work. Even though consistent improvement is observed, it is not significant. Perhaps there are other ways to leverage phonetic information.
Automatic Rank-ordering of Singing Vocals with Twin-neural Network
Chitralekha Gupta, Lin Huang, Haizhou Li
Summary:
In this paper, the authors present a purely engineered way of measuring the singing quality using music-informed features and a Siamese network, which learns to choose the better singer from two performances.
Pros:
- A nice Deep Learning-based method for evaluating the singing quality.
- The authors use public datasets.
Cons:
- The authors tackle a problem that has been widely discussed by musicologists: “What are the objective measures for singing quality?”. Though there has not been a common consensus among singing voice researchers, educators, and performers, the authors claim that there is, referring to only two recent MIR papers. I think some of their claims are too bold to be scientific. ISMIR reviewers should also think musicologically as much as they consider the details from an engineering perspective.
- For the ground truth labels of their first dataset, the authors use crowd-sourced singing quality rankings of the users of a karaoke app (Smule). However, we do not necessarily know that the people involved in voting have enough expertise in singing to be able to judge other performers. I guess the term “ground truth” should be revised.
A Chorus-section Detection Method for Lyrics Text
Kento Watanabe, Masataka Goto
Summary:
This study proposes a sequence labeling method to be used to detect the chorus sections of lyrics of songs using only the text as input. The authors train a BiLSTM network on a large but private dataset with semi-automatically generated chorus-line annotations.
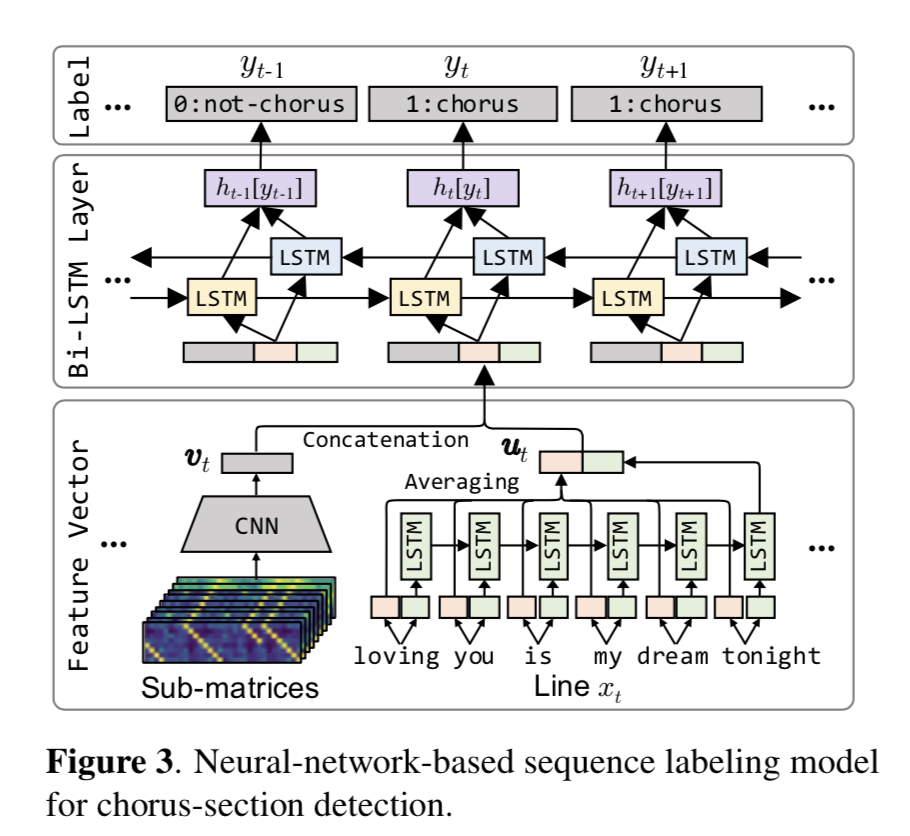
Pros:
- This is the first work on an important computational problem within MIR. Such a robust, generalizable, and scalable model would have a range of applications.
- It shows an example case of an NLP application in MIR.
- There are several open-source tools revealed in the paper.
- The list of features used for this task makes almost complete sense and combining them for sequence labeling is novel.
Cons:
- Both training and evaluation data are private and not accessible by other researchers. The scientific approach of the 21st century requires open science for fairness, transparency, and reproducibility of published results.
- According to the authors, BiLSTMs against MLPs or heuristic-based models are beneficial for sequence prediction, which they state as a contribution of the paper. Well, we knew this already which was shown in several dozens of peer-review papers.
- Among the features used for the task, the only thing that I did not get is the motivation of using “lyrics line syllable count”. Also, the choice of some features could be better justified.
(Notice: The figures in this post are taken from the related papers including their captions to make them more explanatory. Please don’t pay attention to the figure number - this is not in order)