This year saw multiple international conferences go virtual, smitten by the COVID-bug. ISMIR 2020 was no exception to this trend, and while we were disappointed to be unable to meet physically in Montréal, Canada; the organizers did a great job with the virtual format. I attended ISMIR 2020, the 21st International Society for Music Information Retrieval Conference, from the 11th to the 16th of October, 2020. I was delighted to find some fascinating papers related to my current research. This blog post summarizes one such paper that piqued my interest. The paper is titled “Learning to read and follow music in complete score sheet images”; and the authors are Florian Henkel, Rainer Kelz, and Gerhard Widmer, from JKU Linz, Austria.
Score following in raw sheet images
The work presented in this paper aims at score following in sheet music that is given as unprocessed images. The general goal of score following is to determine the current position in the score for an incoming music performance. The authors build upon their previous work presented in ISMIR 20191 and extend the capabilities of the score following model. The novelty of this work lies in the fact that they deal directly with complete raw images of sheet music (although this is done one page at a time). Existing methods for score following either rely on computer-readable representations of the score (such as MIDI or MusicXML), or work with small snippets of the sheet images. While the former representation is not readily available and/or depends on robust OMR, the latter is unable to capture context and disambiguate between different possible matching positions. It also has another constraint that the sheet image excerpt has to correspond partially to the incoming audio excerpt, in the absence of which the tracker is lost and subsequent predictions are incorrect. Additionally, the methods that work with snippets of audio and sheet image need an “unrolled” score representation, i.e. the staves have to be cut out from the sheet image and stitched together in a sequence.
The authors attempt to overcome this limitation by working with entire pages of sheet music images. They extend the work initially proposed in 1 to be able to handle the temporal aspect of score following, i.e. disambiguate multiple positions in the sheet image that match with the audio excerpt. Another recent work has shown the effectiveness frame similarity learning for audio-to-score alignment 2, a task related to score following.
A brief detour: Referring image segmentation
The basic idea is motivated by “referring image segmentation” 3, a task in computer vision that aims to identify a region in an image, given a language expression as the query. To better understand this task, take a look at this figure:

As the figure suggests, given the input images (left) and the corresponding referring expressions (below), the goal of referring image segmentation is to segment out the regions in the image referred to by the expression (right).
Back to score following
The idea discussed above is carried over to the score following task by modelling it as the following question: “Given the incoming audio, which position in the sheet image does it correspond to?”. In other words, the authors treat the incoming audio as the language expression, to extract the region from the sheet image that acts as the entity to reason about.
Specifically, they predict a binary segmentation mask that gives for each pixel in the sheet image page, the probability of it corresponding to the current audio. The authors employ a U-net based architecture for this task, illustrated in the figure below:
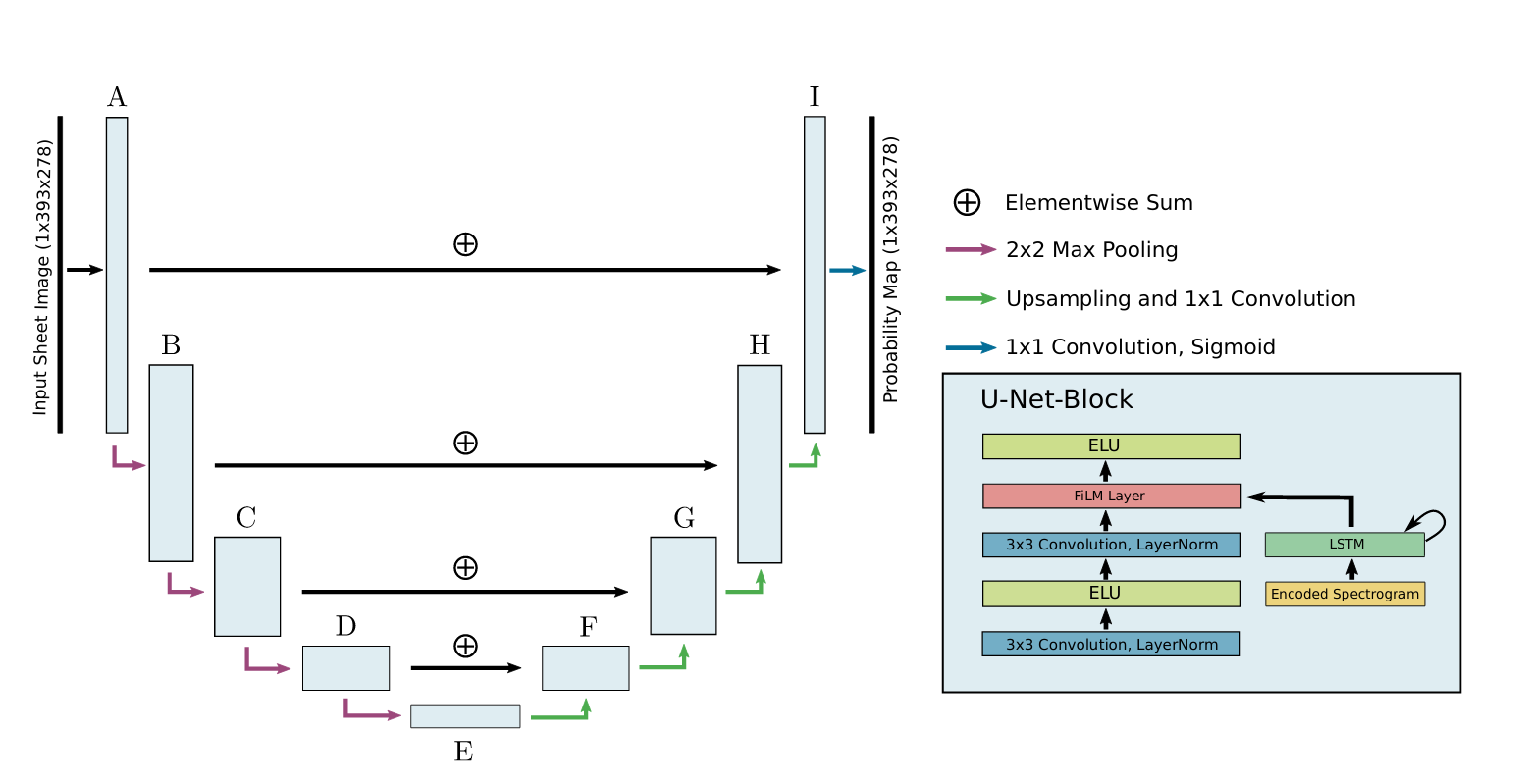
A feature-wise linear modulation layer 4 is also applied before the last activation function, to directly interfere with the learned representation of the sheet image by modulating its feature maps. This helps the CNN to focus on the parts required for segmentation. The FiLM layer is illustrated below:

The results are reported on the MSMD data set, a synthetic dataset containing polyphonic piano music. The authors report that their method outperforms previous methods that are based on snippets of sheet music matched to audio excerpts, as well as an OMR based DTW method. A noteworthy point is that pieces containing several pages of sheet music are split into multiple pieces to aid training. Perhaps future work could deal with entire pieces in one go. All in all, this is a promising paper furthering the research on score following. Some limitations of their method are the inability to handle structural differences like repeats, the implications of the size of the segmentation mask on the granularity of alignment, and generalizing to real recordings.
References
-
Henkel, Florian, Rainer Kelz, and Gerhard Widmer. “Audio-Conditioned U-Net for Position Estimation in Full Sheet Images.” arXiv preprint arXiv:1910.07254 (2019). ↩ ↩2
-
Agrawal, Ruchit, and Simon Dixon. “Learning Frame Similarity using Siamese networks for Audio-to-Score Alignment.” 28th European Signal Processing Conference (EUSIPCO 2020) ↩
-
Liu, Chenxi, et al. “Recurrent multimodal interaction for referring image segmentation.” Proceedings of the IEEE International Conference on Computer Vision. 2017. ↩
-
Perez, Ethan, et al. “FiLM: Visual Reasoning with a General Conditioning Layer.” AAAI. 2018. ↩