From 4th to 8th of May 2020, I attended the ICASSP 2020, short for International Conference on Acoustics, Speech and Signal Processing. Even though it was planned to be held in Barcelona, Spain, the conference moved to a fully virtual format due to the recent COVID-19 induced lockdowns around the world. While this reduced the networking aspect of the event, the fully online conference allowed a higher number of participants, and the free registration for non-authors also facilitated the participation of machine learning enthusiasts worldwide.
Apart from the fantastic tutorials and great keynote talks given by academic and industry researchers from all over the world, the scientific programme included many interesting papers. One of them immediately caught my attention due to the novelty and relation to my own PhD topic. The work I am talking about is Simultaneous Separation and Transcription of Mixtures with Multiple Polyphonic and Percussive Instruments, by Ethan Manilow, Prem Seetharaman and Bryan Pardo, where a multi-task system capable of performing music source separation and transcription simultaneously is proposed.
In this post I would like to talk a little bit more about this paper, summarizing its leading ideas and explaining in my own (and hopefully easier) words the contributions and achievements made by the authors.
Music Source Separation and Transcription
As most of you already know, Music Information Retrieval (MIR) researchers call Music Source Separation the task of separating an audio signal into its constituting sources. The definition of sources, though, vary in the specialised literature, allowing us to divide source separation problems into multiple categories depending on the researcher’s interest. Some examples are source separation algorithms to separate the signal into each constituent isolated single-instrument recording, methods interested in separating only one of the instruments or the vocal track from the “rest”, or even methods to separate harmonic instruments from percussive ones. In this paper, the authors propose a system of the first category. More specifically, their system can separate mixtures with up to 5 instruments into its constituent single-instrument recordings. The instruments they use are piano, guitar, drums, bass and strings. Recently, music source separation has significantly advanced, with many recent deep neural network architectures achieving impressive results for the task. Furthermore, music source separation is a crucial MIR task because it enables other downstream tasks, such as analysis of each separated track, remixing of audio recordings, musical rhythm analysis or beat-tracking, among many others.
Similarly, the task of Automatic Music Transcription challenges MIR researchers to generate any type of notation for the music signal automatically. The type of target notation also varies in the literature, it can be a MIDI piano roll, the score of a particular instrument in the audio signal, or even the full score for the whole piece. In this project, the authors estimate MIDI piano rolls for each source used in the separation task.
Both the tasks have been historically considered the holy grails in the MIR community due to the high level of difficulty involved. In the presence of polyphonic instruments, where multiple notes can be played simultaneously by each instrument, the challenges are even more complicated due to the overlap of the harmonics and of the timbre features in the time-frequency representation of the music signal.
The Cerberus Network
The main contribution of this work is the fact that instead of performing the separation and the transcription independently or performing the transcription as a downstream task after source separation, the authors proposed to jointly perform both tasks using a single neural network in a multi-task scenario. The authors are able to leverage the similarities between those two tasks and use a shared latent representation, so both of them can be performed simultaneously.
The paper proposes a deep neural network architecture built upon the Chimera Network1, which was previously proposed exclusively for source separation. Originally, in the Chimera network, a mixture magnitude spectrogram of size \(T\times F\) is used as input to a stack of Bidirectional Long Short-Term Memories (LSTMs) and 2 outputs are estimated. The first is the typical output of mask-based source separation algorithms: a mask with the same dimension as the input, whose element-wise multiplication by the original mixture magnitude spectrogram recovers the magnitude spectrogram of the target source. The other output is an embedding space of dimension \(TF\times 20\), where every row represents a projection of a time-frequency bin of the mixture spectrogram into a 20-dimensional space. The projection is such that bins that primarily contain energy from the same source are projected closer to each other while bins belonging to different sources are located far apart. This embedding technique is called Deep Clustering2 and can be seen as a regularisation technique for the source separation in the Chimera architecture.
In this work, the authors extend this architecture by adding a new output to it. They named it Cerberus Network in an allusion to the three-headed guardian dog from the Greek mythology. In the Cerberus network, the new output is the direct piano roll of each of the sources of the mixture. The piano roll is trained using \(L2\)-distance from the original piano roll of each instrument using a total of 88 possible MIDI notes. In summary, the final loss of the proposed architecture is a linear combination of the Deep Clustering (DC), Mask Inference (MI) and Transcription (TR) losses such as:
The figure below shows an overview of the proposed system. Note the 3 heads (outputs) in the network. Two are responsible for the two tasks mentioned above, and the other is treated as a regularisation to improve the network’s performance.
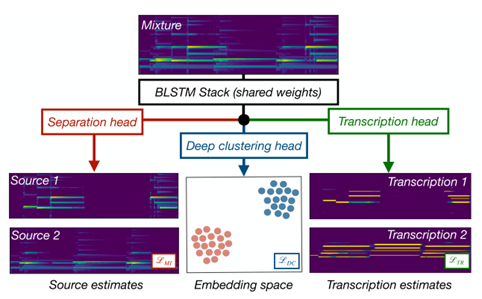
Overview of the Cerberus multi-task system3.
Experiments and Results
The authors trained their system using the Slack2100 dataset4 by creating 4 sets of synthesized mixtures. The instrument combinations for the four sets were piano + guitar (set 1), piano + guitar + bass (set 2), and piano + guitar + bass + drums (set 3), and piano + guitar + bass + drums + strings (set 4). Moreover, they also implemented a version of a (piano + guitar) model trained and evaluated on real-world recordings audio of isolated notes from those two instruments by creating incoherent (random) mixtures of data from MAPS5 and GuitarSet6 datasets. The authors compared the Cerberus network with all the combinations of models using just one or two of the three-loss terms from Eq 1. They show that the Cerberus network is able to maintain the separation performance of the Chimera network and improve the transcription F1-measure by up to 4% if compared to a model trained only with the transcription output using \(\mathcal{L}_{\mathrm{TR}}\).
In the project’s official website you can find not only the original paper but also listen to audio samples of estimated by their system and check the complete evaluation for the music source separation and transcription.
Conclusion
The authors showed that it is possible to jointly learn how to separate and transcribe up to five instruments with a single network. Their multi-task system was able to leverage a shared latent representation by exploiting the fact that separation and transcription are complementary related tasks.
From my point of view, I believe that their approach is interesting and shows the power of multi-task systems and how each task can help in solving other related tasks. This paper is definitely worth a full read. Keep posted for the next blog post!
References
-
Y. Luo, Z. Chen, J. Hershey, J. Le Roux and N. Mesgarani “Deep Clustering and Conventional Networks for Music Separation: Stronger Together” In IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP) IEEE (2017) New Orleans, USA https://doi.org/10.1109/ICASSP.2017.7952118 ↩
-
J. Hershey, Z. Chen, J. Le Roux and S. Watanabe “Deep Clustering: Discriminative Embeddings for Segmentation and Separation” In IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP) IEEE (2016) Shangai, China https://doi.org/10.1109/ICASSP.2016.7471631 ↩
-
E. Manilow, P. Seetharaman and B. Pardo “Simultaneous Separation and Transcription of Mixtures with Multiple Polyphonic and Percussive Instruments” In IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP) IEEE, (2020)Barcelona, Spain https://doi.org/10.1109/ICASSP40776.2020.9054340 ↩
-
E. Manilow, G. Wichern, P. Seetharaman and J. Le Roux “Cutting Music Source Separation Some Slakh: A Dataset to Study the Impact of Training Data Quality and Quantity” In IEEE Workshop on Applications of Signal Processing to Audio and Acoustics (WASPAA), (2019) New Paltz, USA https://doi.org/10.1109/WASPAA.2019.8937170 ↩
-
V. Emiya, R. Badeau and B. David, “Multipitch Estimation of Piano Sounds Using a New Probabilistic Spectral Smoothness Principle” In IEEE Transactions on Audio, Speech, and Language Processing vol. 18 no. 6, (2009) pp. 1643–1654 https://doi.org/10.1109/TASL.2009.2038819 ↩
-
Q. Xi, R. Bittner, J. Pauwels, X. Ye and J. P. Bello “Guitarset: A Dataset for Guitar Transcription” In International Society for Music Information Retrieval (ISMIR) (2018) Paris, France https://doi.org/10.5281/zenodo.1492449 ↩