The topic of this post is the carbon footprint of Artificial Intelligence (AI). I thought this was a relevant topic to discuss as we, as researchers, are part of the emission process, even if we are mostly unaware of it. I believe it is ethically essential to be aware of the consequences that can derive from training our large deep learning models and discuss guidelines and best practices for our research community.
Climate Change
First, let us recall the consequences of climate change, even if they are under our eyes every day. The United Nations declared climate change a “defining crisis of our time”1, and most climate scientists agree that human activity is its main driver2. However, the effects of climate change are not only the rise of temperatures and the melting of glaciers, but also:
- food and water emergency due to soil degradation and rise of temperatures;
- extreme meteorological events, such as, heatwaves, hurricanes, which are becoming more frequent and intense. 90% of them are classified as weather- and climate-related.
This creates competition for land, food, and water, leading to socio-economic tensions and mass displacement1. More than 140 million people, mostly from the south of the world, will be forced to migrate by 20501. According to a Stanford University research3, the economic gap between the world’s richest and poorest countries is 25% larger today than it would have been without global warming.
Urgent actions are needed to avoid an environmental catastrophe, including reducing emissions to zero by the middle of the twenty-first century and limiting the average global warming to 1.5 °C1. Technology has, of course, a central role in fighting this crisis.
The Role of AI
In this light, it has become an urgent matter to consider the dual role of the AI technology in the crisis. On one hand, it can help reduce climate change effects by, for example, modelling and developing solutions to avoid it. On the other hand, the AI is itself a significant emitter of carbon.
Below you can see a visual map extracted from an essay of 2018 entitled Anatomy of an AI system4 that shows the impact of an AI device on a global scale. The authors took as an example Amazon Echo and followed its impact from manufacturing to usage. They analysed its impact in terms of social work, data, and resources required during its lifespan.
Map extracted from Anatomy of an AI system4
In the whole map, the location where we, as researchers, come into the game and play an active role is the small section below, related to training an AI system and eventually preparing and labelling data.
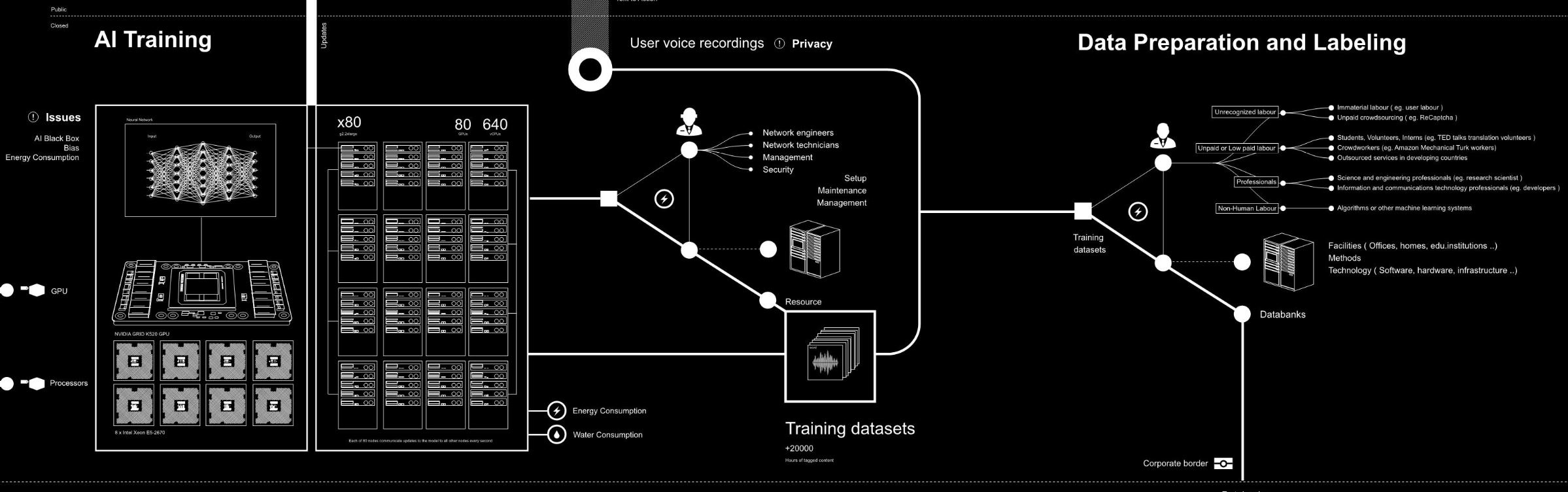
Details of the map extracted from Anatomy of an AI system4
Red vs Green AI
In 2019, a team from MIT analysed some Natural Language Processing (NLP) models available online5. The researchers estimated the energy consumption (in kilowatts) required to train them and converted the numbers into approximate carbon emissions and electricity costs. They estimated that the carbon footprint of training a single big language model is equal to around 300,000 kg of carbon dioxide emissions, which is orders of magnitude higher than other familiar consumptions. Furthermore, the authors also quantified the computational cost of Research and Development (R&D) for a new NLP model. This cost is the one we, as researchers and engineers, should primarily consider, as it reflects the actual carbon footprint of a project. In the figure below, you can see the details of the estimated CO\(_2\) emissions from training standard NLP models compared to everyday consumption.
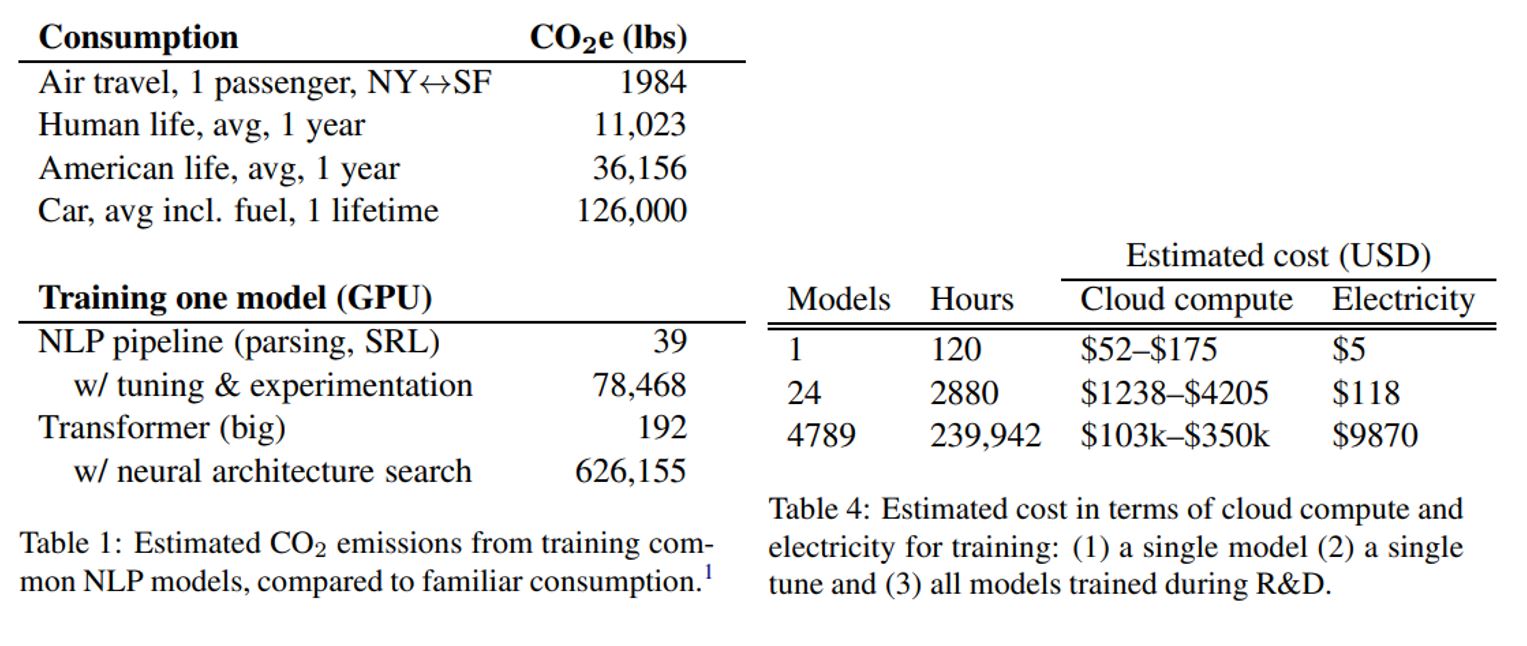
Tables of carbon dioxide emission. Extracted from 5
In a paper from 2019, Roy Schwartz and collaborators observed that a linear gain in performance requires an exponentially larger model leading to substantial carbon emissions6. They called this trend ‘red AI’, that is, ‘buying’ better results using massive computing. Their study enumerated three factors making AI research red:
- the cost of running the model on a single example;
- the training dataset size, which controls the number of times the model is run;
- the number of hyperparameters, which controls how many computations are necessary to train the model.
They analysed papers from top conferences and observed that the majority prioritised accuracy over efficiency (90% from the Computational Linguistics Conference 2018, 80% from NeurIPS 2018, and 75% from the Conference on Computer Vision and Pattern Recognition 2019). In the same paper, the authors also defined the term ‘green AI’ as “AI research that yields novel results without increasing or, ideally reducing, computational cost”. Green AI considers efficiency as a critical evaluation criterion and is considered an opposite term to red AI. Ideally, this type of research would level the possibilities of academia versus big tech companies, whose research is often facilitated by impressive computational resources.
A virtuous example in audio research is SuDoRM-RF7, a novel deep architecture for efficient universal sound source separation. It extracts multi-resolution temporal features through successive depth-wise convolutional down-sampling and aggregates them using a nonparametric interpolation scheme. This way, the authors can significantly reduce the required number of layers while still effectively capturing long-term temporal dependencies. The proposed model performs similarly or even better than state-of-the-art models while requiring significantly less computational resources in terms of the number of trainable parameters, number of floating-point operations, memory allocation, and time.
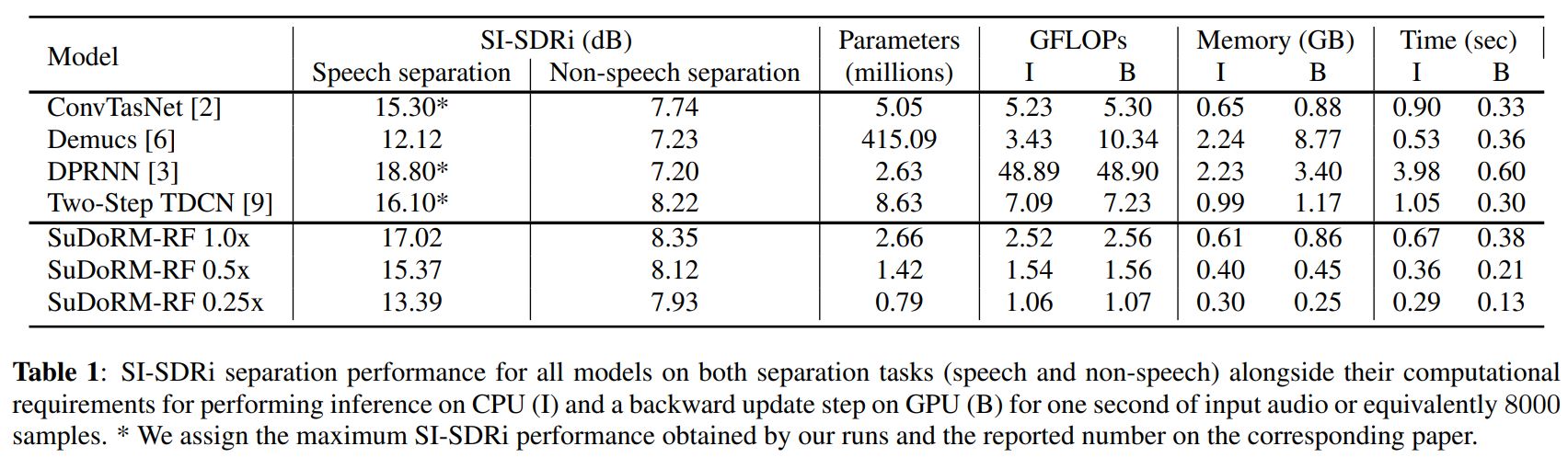
Separation performances alongside their computational requirements for performing inference on CPU (I) and a backward update step on GPU (B) for one-second long audio input or the equivalent of 8000 samples7.
Even if this is a virtuous example, there is no estimate of carbon emissions and energy consumption. Mainly, the problem is the absence of a standard of measurement and the intrinsic difficulties in measuring it.
The emissions are related to the training server’s location and the energy grid it uses, the training procedure’s duration and the training’s hardware. Thus, it is difficult to measure and requires specific knowledge. Therefore, we can take advantage of libraries and tools that do the work for us, for example:
Quantify the Energy Accounting
The consumed energy consists of the amount of energy needed to power the computational system and it is measured in Joules (J) or Watt-hours (Wh). It is given mostly by the cooling of the system and by the server/storage power consumption9:
- cooling (50%)
- lighting (3%)
- power conversion (11%)
- network hardware (10%)
- server/storage (26%)
We can further break down the server and storage component into DRAM, CPUs, and GPUs’ contributions. Accurate accounting for all these components requires complex modelling and varies depending on workload. Most carbon/energy trackers consider DRAM/CPUs/GPUs consumption and account for the other components through the PUE (Power Usage Effectiveness) factor9. This factor rescales the power metrics by an average projected overhead of different elements. This way, one can evaluate the impact of her/his experiment only without considering background processes.
Carbon emissions are typically measured in CO\(_{2}\)eq, which is the amount of carbon dioxide released into the atmosphere due to the project9. Sometimes (especially in regulations), it is considered the financial impacts through carbon’s social cost (SC-CO\(_2\)), which measures the long-term damage done by CO\(_2\) 9. To measure it, one should use the per-country social cost of carbon, which accounts for the risk profiles of different countries.
We can estimate carbon emissions by understanding the local energy grid’s carbon intensity and the system’s energy consumption9. The carbon intensity corresponds to the grams of CO\(_{2}\)eq emitted per kWh of energy used and is determined by the energy sources supplying the grid:
- coal power: 820 gCO\(_{2}\)eq / kWh
- hydro-electricity: 24 gCO\(_{2}\)eq / kWh
Thus, running our job in countries where the energy supply is green can be crucial. It is not necessary to eliminate computation-heavy models, as shifting training resources to low carbon regions can immediately reduce carbon emissions with little impact on us9. (e.g., training the same model in Quebec rather than in Lettonia can reduce CO\(_{2}\)eq by 30 times!)
Guidelines
In conclusion, we, as researchers, should think about:
- report training time, computational resources, and sensitivity to hyperparameters;
- make a cost-benefit (accuracy) analysis of our models;
- prioritise computationally efficient hardware and algorithms;
- quantify energy consumption and carbon emission;
- move jobs to low carbon regions;
Check out these excellent initiatives:
Looking forward to seeing something similar in the MIR community!
References:
-
The United Nations (UN), “The Climate Crisis – A Race We Can Win” In https://www.un.org/en/un75/climate-crisis-race-we-can-win ↩ ↩2 ↩3 ↩4
-
“The Climate Reality Project” In https://www.climaterealityproject.org/ ↩
-
J. Garthwaite, “Climate change has worsened global economic inequality” In Stanford Earth (2019) https://earth.stanford.edu/news/climate-change-has-worsened-global-economic-inequality#gs.g3u2y5 ↩
-
K. Crawford and V. Joler, “Anatomy of an AI System: The Amazon Echo As An Anatomical Map of Human Labor, Data and Planetary Resources,” In AI Now Institute and Share Lab (2018) https://anatomyof.ai/ ↩ ↩2 ↩3
-
E. Strubell, A. Ganesh and A. McCallum, “Energy and Policy Considerations for Deep Learning in NLP” In ArXiv Preprint (2019) https://arxiv.org/abs/1906.02243 ↩ ↩2
-
R. Schwartz et al. “Green AI.” In ArXiv Preprint (2019) https://arxiv.org/pdf/1907.10597.pdf ↩
-
Tzinis, Efthymios, Zhepei Wang, and Paris Smaragdis. “SuDo RM-RF: Efficient Networks for Universal Audio Source Separation.” In IEEE 30th International Workshop on Machine Learning for Signal Processing (MLSP) IEEE, (2020) https://arxiv.org/pdf/2007.06833.pdf ↩ ↩2
-
A. Lacoste et al. “Quantifying the carbon emissions of machine learning” In ArXiv Preprint arXiv:1910.09700 (2019) https://arxiv.org/pdf/1910.09700.pdf ↩
-
P. Henderson et al. “Towards the Systematic Reporting of the Energy and Carbon Footprints of Machine Learning.” In ArXiv Preprint (2020) https://arxiv.org/pdf/2002.05651.pdf ↩ ↩2 ↩3 ↩4 ↩5 ↩6 ↩7
-
L. F. W. Anthony, B. Kanding, and R. Selvan “Carbontracker: Tracking and Predicting the Carbon Footprint of Training Deep Learning Models.” In ArXiv Preprint (2020) https://arxiv.org/pdf/2007.03051.pdf ↩