In this blog post, we take a look into one of the best-performing systems in hybrid speech recognition which was presented in the paper Transformer-based Acoustic Modeling for Hybrid Speech Recognition.1 The transformer architecture has been a popular neural network design since its introduction2. In this paper, the authors successfully implement the transformer architecture in a hybrid speech recognition setting and managed to get competitive results with the state of the art.
Before going into details of the hybrid transformer model, let’s give a little bit of context about speech recognition.
Speech recognition can be considered as the task of predicting the most likely word sequence given an acoustic observation, which can be expressed by the equation below:
In this equation the variable \(\mathrm{O}\) can be vectors of spectrogram, MFCC features, waveform signal, etc. \(P(\mathrm{O} \vert \mathrm{w})\) and \(P(\mathrm{w})\) are referred as the acoustic and the language model respectively.
There are two popular approaches for predicting this word likelihood in the state-of-the-art in automatic speech recognition (ASR) systems: Hybrid-ASR and End-to-end ASR. In the latter, the goal is to train a deep neural network to learn the complete mapping between acoustic feature vectors and alphabetic characters that form words. End-to-end ASR paradigms such as encoder-decoder or neural transducer approaches have been experiencing growing popularity due to their simplicity and them requiring lesser domain knowledge for building a pipeline.
Hybrid-ASR is usually composed of separate acoustic, language, and pronunciation models and generally uses a Finite State Transducer (FST) to decode given acoustic observations into word sequences3. Even though the hybrid approach might require domain knowledge from multiple disciplines, like speech, linguistics and phonetics, it has been the preferred option for many industrial applications due to its robustness and requiring less data for a good performance.
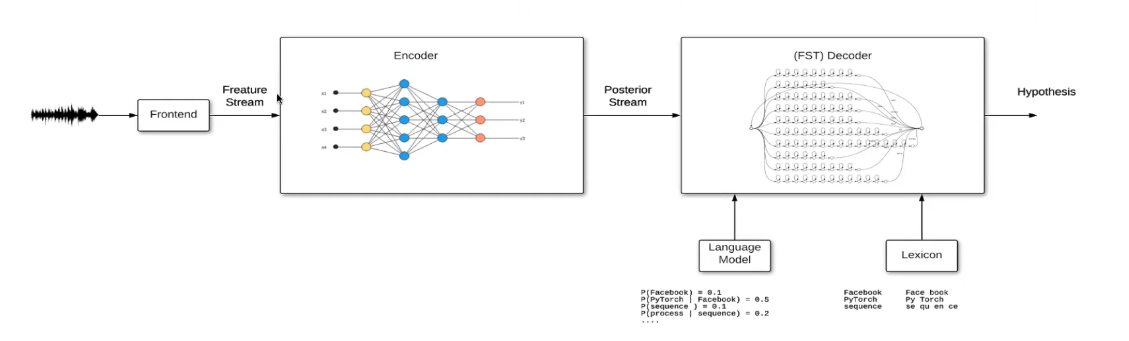
The paper of subject targets at adapting a successful strategy in one paradigm - end-to-end ASR - to another - hybrid-ASR. The authors achieve this by implementing the Transformer architecture (figure below) to build the acoustic model in a hybrid-ASR setting.
Transformer architecture is based on the self-attention mechanism which is an operation within neural networks that applies a weighted summation over a certain context window of the input node of a hidden layer. The weights of the summation are learned through gradient optimization which updates the parameters of a dot product between input (key) and context (query) matrices. Self-attention is usually applied with multiple heads to learn more diverse information from data. This overall mechanism is referred to as multi-head (self)-attention, which is denoted as MHA in the figure below.
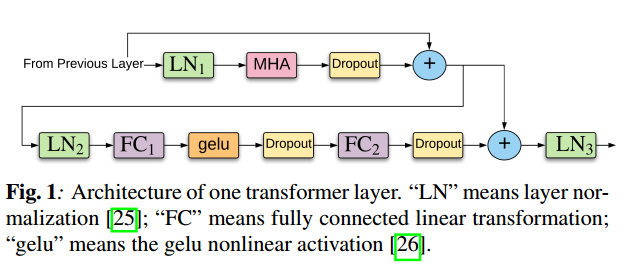
Self-attention comes with two major advantages. The first one is that the computational complexity to learn temporal context dependencies is lesser compared to RNNs and CNNs. Secondly, the attention operation can be parallelized, which makes optimization easier.
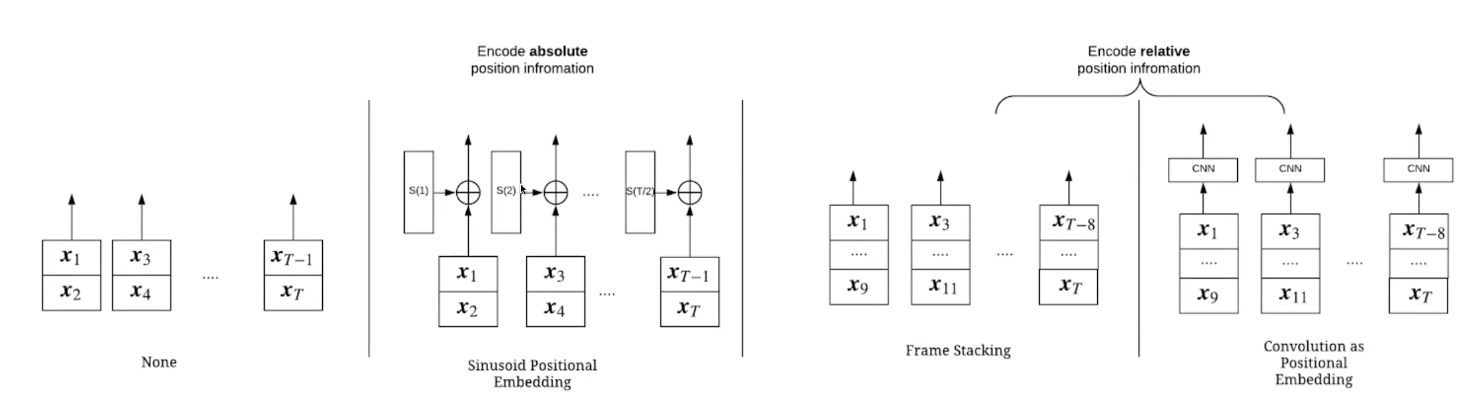
On the other hand, the transformer has one major disadvantage. The output of the transformer layer is permutation invariant to input vectors, i.e the order of the input vector sequence is not encoded in the attention operation. The authors circumvent this problem through frame stacking and adding a 2D CNN (namely a pre-trained 2 layer VGG model) in the backend to serve as positional encoders 4.
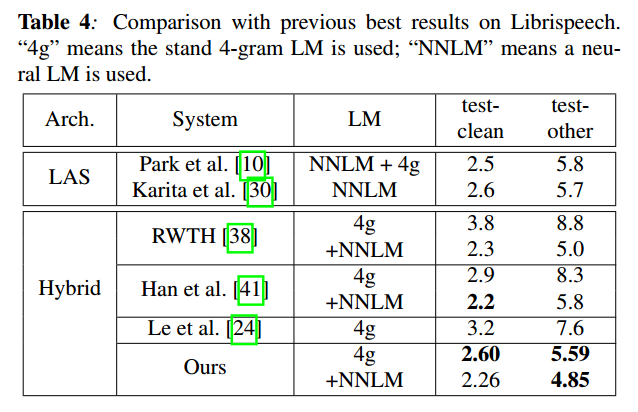
The performance of the so-called hybrid-Transformer shows better Word Error Rate results compared to some other strong speech recognition models (table below). The authors achieve their best results via sequence discriminative training of chenones5 and RNNLM lattice rescoring which is denoted as one of the best resulting ASR systems by the date of this blog post.
References
-
Wang, Yongqiang, et al. “Transformer-based acoustic modeling for hybrid speech recognition.” ICASSP 2020-2020 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, 2020. ↩
-
Vaswani, Ashish, et al. “Attention is all you need.” Advances in neural information processing systems. 2017. ↩
-
Mohri, Mehryar, Fernando Pereira, and Michael Riley. “Weighted finite-state transducers in speech recognition.” Computer Speech & Language 16.1 (2002): 69-88. ↩
-
K. Simonyan and A. Zisserman, “Very deep convolutional networks for large-scale image recognition,” arXiv preprint arXiv:1409.1556, 2014. ↩
-
Le, Duc, et al. “From senones to chenones: Tied context-dependent graphemes for hybrid speech recognition.” 2019 IEEE Automatic Speech Recognition and Understanding Workshop (ASRU). IEEE, 2019. ↩