Audio source separation consists of recovering one or more target sources from an observed audio mixture. A straightforward example we can think about is the cocktail party problem where several people are talking simultaneously and we want to enhance just one speaker and suppress everything else.

Cocktail party problem (figure from Medium post by Furkan Kaya)
Source separation can also be applied in music processing where the mixtures are songs and the sources we want to separate are individual instruments, e.g. bass, vocals, guitar, etc. This problem is highly relevant for many MIR tasks such as music transcription, lyrics alignment, etc. which often need a preliminary separation stage. Separating instruments also allows Karaoke creation, upmixing, and remixing.
In this blog post, we give an overview of trends in source separation research which we observed at the 2019 IEEE Workshop on Applications of Signal Processing to Audio and Acoustics conference (WASPAA) in New Paltz, NY, USA.
From Filtering To Synthesis
Source separation is often performed by time-frequency masking where unwanted time-frequency components are removed from a mixture spectrogram. The estimation of such masks has been the research goal for a long time. A successful method was Nonnegative Matrix Factorization (NMF) which can be classified as linear, knowledge-driven, and unsupervised. Today, state of the art sources separation methods estimate masks using Deep Learning, i.e. they are non-linear, data-driven, and supervised.
Filtering the mixture intrinsically degrades the source and introduces artifacts, especially when the signal to noise ratio is low. A new and promising trend is to synthesize the source of interest instead of filtering the mixture. Two WASPAA papers dealt with this approach. Rather than reconstructing the target waveform exactly, the goal is to produce a signal that sounds similar. The generated waveform might differ from the target regarding details that are not critical for perception.
In [1], an LSTM based encoder processes mel-spectrograms of noisy speech and extracts 12 features per frame, which contain only information about clean speech. This learned representation is used as input to the WaveNet, a model for speech generation operating in the time domain. Because standard metrics for speech enhancement directly compare the separated with the ground truth speech signal they are not appropriate for the generative approach. Hence, the authors conduct listening tests and show that their approach can produce perceptually well-separated speech signals even if the waveform differs from the ground truth.
Similarly, in [2] the authors predict clean log mel-spectrograms from noisy inputs and then generate speech with WaveNet and WaveGlow. The objective and subjective evaluation confirm the effectiveness of the “synthesize” approach. Its advantage is that generated speech does not contain noise, so the output signal will always sound like clean speech. However, when the observed signal is very noisy the generated speech contains mistakes in the form of mumbled unintelligible speech segments. Another challenge is to maintain the speaker characteristics.
In [3] another two-step approach to speech enhancement is investigated. First, a clean speech spectrogram is predicted through masking using an LSTM network. The clean speech is likely to be distorted due to the limitations of masking. As a second step, CNN is employed to map the distorted speech spectrogram to the corresponding clean speech spectrogram, which the authors call speech restoration. It is shown that this second step repairs some degradations introduced by the masking step.
Generalizing Data-Driven Source Separation
Data-driven approaches have shown to perform extremely well on very specific tasks for which they are trained, e.g. separating the singing voice from rock songs. However, we are now more interested in designing and training models that can perform the task in a more general setting.
The authors of [4] proposed a multichannel speech enhancement method based on a long short-term memory (LSTM) recurrent neural network which processes each frequency band individually for each channel. This allows exploiting temporal and spatial differences of speech and noise (speech is non-stationary and coherent, while noise is stationary and less-spatially coherent) allowing the network to generalize well to unseen speakers and noise types.
In a paper called “Universal Sound Separation” [5], the authors modified [6], a model originally developed for speech enhancement, in order to be able to separate arbitrary sounds such as crawling insects, animal calls, creaking doors, construction noises, musical instruments, speech, or composed music. One of the findings confirms that very general sound separation is an extremely difficult task: while longer FFT windows lead to better performance for speech separation, shorter windows are preferred for separating other sounds.
Classical supervised source separation relies on training data consisting of mixtures and the corresponding isolated sources. Often, we do not have access to large amounts of paired data. An interesting solution to this problem was presented by the authors of [7], who propose a style transfer approach to source separation. This means a model learns a general mapping between the space of mixed sources and the space of clean sources without requiring that the clean source examples are contained in the mixtures. Mixture and clean source spectrograms are mapped to the same latent space by two distinct variational autoencoders as shown in Figure 1. At test time, the mixture space encoder maps the mixture to the latent space and then the clean source decoder computes the prediction of the clean source.
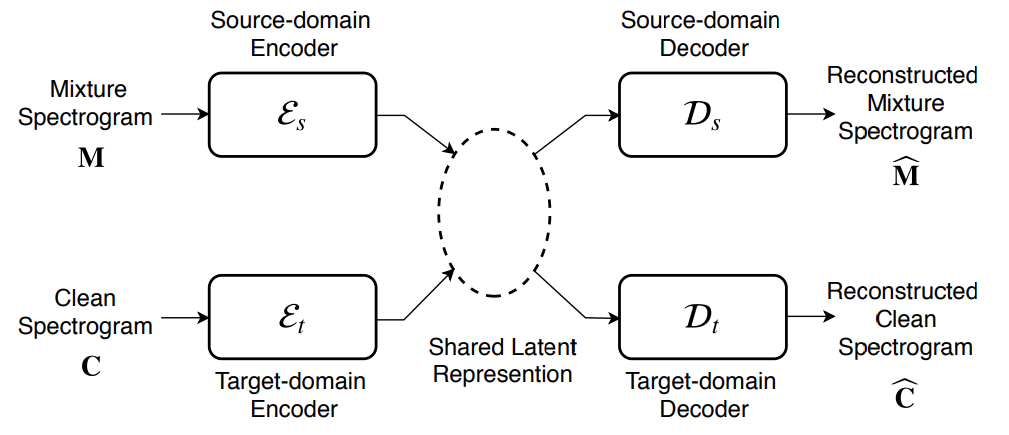
Figure 1: Overview of a style transfer approach to source separation[^7]
Evaluation metrics
It is well known that currently used metrics for source separation and speech quality evaluation have strong limitations. For example, they do not correlate well with human perception, they are computationally expensive, and they need a reference signal for comparison. Some papers tackled these problems.
The authors of [8] found that only two Model Output Variables (MOV) of the perceptual measurement scheme PEAQ are enough to reflect human perception well. The MOVs are the average distorted block and the average modulation difference. Based on these two timbre features human perception can be predicted with a reduced computational cost.
Another research team trained a Convolutional Neural Network (CNN) to predict the perceptual quality of speech [9]. They propose an intrusive and a non-intrusive version of their approach, i.e. with and without using a reference signal. A challenge for this interesting approach is collecting large ground truth data through listening tests and diverse data containing many different degradation types.
A similar non-intrusive approach for speech quality assessment has been investigated in [10], where a CNN is trained to predict PESQ scores and simultaneously classify the observed speech signal to different PESQ score ranges as classes. This multi-task approach was found to improve performance.
The objective evaluation metrics SDR, SAR, and SIR are usually computed on non-overlapping frames of one second length for musical source separation. A strong limitation is that they are not defined for frames where the target or the prediction is silent, which is often the case for the singing voice. In [11] two metrics are introduced to complement the standard metrics regarding this issue. The Predicted Energy at Silence (PES) metric measures the energy in the prediction for frames where the target is silent. The Energy at Predicted Silence (EPS) metric measures the energy in the true source for frames where silence is predicted.
Attention Mechanism
The attention mechanism was originally developed for machine translation to cope with different word orders in different languages. It is also widely used in automatic speech recognition and becomes increasingly popular for many more audio related tasks. Hence, also some WASPAA papers proposed using attention for various purposes.
In [12], attention was incorporated into the Wave-U-Net for speech enhancement. It is used in the skip connections between encoding and decoding layers with the same time resolution to choose the relevant elements of the encoder feature maps for the decoder side. The attention mechanism learns to focus on features belonging to regions where speech is active. The authors show that this leads to improved performance for speech enhancement.
Furthermore, in [11] attention is employed for weakly informed audio source separation. The idea is to exploit additional information about the singing voice that is not aligned to the audio. The proposed model can exploit such weak side information and jointly align it to the audio using attention.
References
[1] Chinen M., Kleijn WB., Lim FSC., and Skoglund J.. Generative speech enhancement based on cloned networks. IEEE Workshop on Applications of Signal Processing to Audio and Acoustics, 2019.
[2] Maiti S. and Mandel MI.. Parametric resynthesis with neural vocoders. IEEE Workshop on Applications of Signal Processing to Audio and Acoustics, 2019.
[3] Strake M., Defraene B., Fluyt K., Tirry W., Fingscheidt T. Separated noise suppression and speech restoration: LSTM-based speech enhancement in two stages. IEEE Workshop on Applications of Signal Processing to Audio and Acoustics, 2019.
[4] Li, X. Horaud, R. Multichannel speech enhancement based on time-frequency masking using subband long short-term memory. IEEE Workshop on Applications of Signal Processing to Audio and Acoustics, 2019.
[5] Kavalerov I., Wisdom S., Erdogan H., Patton B., Wilson K., LeRoux J., and Hershey J.. Universal Sound Separation. IEEE Workshop on Applications of Signal Processing to Audio and Acoustics, 2019.
[6] Luo Y., Mesgarani N.. Conv-TasNet: Surpassing Ideal Time–Frequency Magnitude Masking for Speech Separation. IEEE Workshop on Applications of Signal Processing to Audio and Acoustics, 2019.
[7] Venkataramani S., Tzinis E., and Smaragdis P.. A style transfer approach to source separation. IEEE Workshop on Applications of Signal Processing to Audio and Acoustics, 2019.
[8] Kastner T. and Herre J. An efficient model for estimating subjective quality of separated audio source signals. IEEE Workshop on Applications of Signal Processing to Audio and Acoustics, 2019.
[9] Gamper H., Reddy C., Cutler R, Tashev I., Gehrke J. Intrusive and non-intrusive perceptual speech quality assessment using a convolutional neural network. IEEE Workshop on Applications of Signal Processing to Audio and Acoustics, 2019.
[10] Dong X. and Williamson D. S. A classification-aided framework for non-intrusive speech quality assessment. IEEE Workshop on Applications of Signal Processing to Audio and Acoustics, 2019.
[11] Schulze-Forster K., Doire C., Richard G., and Badeau R.. Weakly Informed Audio Source Separation. IEEE Workshop on Applications of Signal Processing to Audio and Acoustics, 2019.
[12] Giri, R., Iski U., Krishnaswamy A.. Attention wave-u-net for speech enhancement. IEEE Workshop on Applications of Signal Processing to Audio and Acoustics, 2019.