This post has been adopted from Ondřej’s blog.
I’m very happy that our paper ‘Supervised symbolic music style translation using synthetic data’ has been accepted to ISMIR 2019 and I’m looking forward to presenting it this November. Today, I would like to give an overview of the paper, and also offer a slightly different perspective by explaining how I approached the task of music style transformation as someone coming from a machine translation background.
The general goal of music style transformation is to change the style of a piece of music while preserving some of its original content (i.e. making sure that the piece is still clearly recognizable). In music, style can refer to many different things; in our case, we focus on the style of the accompaniment in different jazz and popular music genres (something that could also be called groove). The idea then is to change the style of a song by generating a new accompaniment for it.
I should emphasize that we are working with symbolic music (MIDI) rather than audio. This allows us to avoid the difficulties that come with generating audio and also makes it easier to evaluate the outputs.
Samples
Let’s first hear the system in action. The playlist below contains three versions of each excerpt (each of them is originally a MIDI file):
- The original song we fed to our system.
- The accompaniment generated by our system. This is the combined output of a ‘bass’ model and a ‘piano’ model.
- The same accompaniment, but mixed with the original melody (manually extracted).
From language to music
Since most of my previous work had been on machine translation – i.e. automatic translation between human languages –, it seemed natural to approach style transformation as a machine translation problem. However, applying machine translation (MT) techniques to musical styles is not straightforward. An MT system typically requires a large parallel corpus, i.e. a collection of texts in language \(L_1\) along with their translations into language \(L_2\). Such a corpus is usually aligned on the level of sentences, which allows us to train a system to translate each source sentence to the corresponding target sentence. To apply the same approach to music, one would, by analogy, need a huge parallel corpus of songs in style \(S_1\) with covers in style \(S_2\), which unfortunately doesn’t exist.
Even though unsupervised translation techniques exist (requiring little or no parallel data), they rely on an important assumption, which is that words/sentences in \(L_1\) and \(L_2\) can be mapped to a shared feature space where their distributions will match. (This is a bit like trying to decipher an unknown language just by looking at how often different words and phrases occur together, and then somehow mapping that to a language you know.) This can only work if the training texts in \(L_1\) and \(L_2\) are from the same domain (i.e. on the same set of topics); just imagine trying to match the distribution of words in French recipes to German children’s books!
Sadly, it’s not clear at all that such an assumption should hold for music, given the fact that different musical styles may have completely different characteristics (similarly to texts from different domains). This could be one of the reasons some of the recent attempts at unsupervised music style translation1,2 haven’t been as successful as one might hope (especially considering the successes of style transfer for images3).
What is style?
Another problem with the style translation task is that it’s not always clear what we mean when we talk about style. There are many aspects to musical style – e.g. composition, arrangement, performance – and we should be clear about which of them we want our algorithm to change. (If we tried to change all of them, we probably wouldn’t recognize the original piece anymore!) This is, however, hard to control, especially with unsupervised learning.
For example, consider the recent ‘Universal Music Translation Network’4 by Facebook Research, which makes use of unsupervised translation techniques. Even though the capabilities of this model are very impressive (the best I’ve seen so far), it seems to be mostly just changing the instrumentation and leaving other musical aspects largely intact. Notice how the jazz guitar example set to ‘Beethoven Piano’ sounds a lot like jazz piano and pretty much not like Beethoven. This shows that the approach is not as ‘universal’ as claimed since in this case it seems to work on one level only and it’s not clear how to control this (e.g. to make it focus more on aspects like harmony or groove).
Band-in-a-Box to the rescue
To sum up, unsupervised translation is tricky to pull off; on the other hand, supervised translation requires large amounts of aligned training examples. I decided to work around the latter issue by creating a synthetic training dataset using the Band-in-a-Box software, which allows generating song accompaniments in many different styles. To give you an idea of what Band-in-a-Box can do, here are accompaniments in two different styles, generated based on the same blues chord sequence:


The bass and piano track of a 12-bar blues accompaniment, rendered as a ‘jazz swing’ (left) and as a ‘samba’ (right). The input chord sequence is shown at the top.
How can we use this to perform style translation? The idea is simple: Given the chord charts of a set of songs, we can use Band-in-a-Box to generate an accompaniment for these songs in two different styles \(S_1\) and \(S_2\) and then train a neural network to translate from \(S_1\) to \(S_2\). However, that alone isn’t very interesting, because such a model is likely only going to work on Band-in-a-Box-generated inputs in style \(S_1\). I wanted to be able to handle real music, ideally in a range of different styles, so I instead picked 70 different Band-in-a-Box styles and trained my network to translate between all the different style pairs.
The whole training pipeline then looks like this:
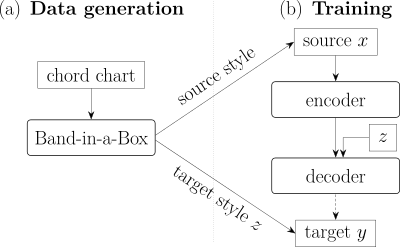
The model is trained to predict the target-style segment \(y\) given a source segment \(x\) and the target style \(z\). Both \(x\) and \(y\) are accompaniments generated by Band-in-a-Box.
The model has an encoder-decoder architecture, with the encoder computing a style-independent representation and the decoder generating the output in a given target style (provided as an embedding vector \(z\)). The trick here is that there is one single encoder, shared for all the source styles. As you can hear from the examples, this was enough to make the model generalize to a wide range of different inputs, and even deal with inputs that include a melody (although the output is still only an accompaniment).
The model
We used a model based on RNN sequence-to-sequence (‘seq2seq’) models with attention.5 This is a very popular neural network architecture which was, until recently, the state of the art in machine translation. There are a couple of elements here which may be a bit difficult to grasp, so I do not aim to explain the architecture in detail. Instead, I recommend this blog post as a pretty comprehensive introduction.
In short, the classical seq2seq model consists of an RNN encoder and an RNN decoder. The encoder computes an intermediate representation of the input sequence and the decoder then generates the output sequence based on this representation. The main difference between seq2seq and our model is that we do not input a sequence of tokens, but a piano roll (a binary matrix indicating which notes are active at each time); for this reason, we use a different encoder architecture, consisting of a convolutional network (CNN) followed by a recurrent network (RNN), instead of just an RNN. The decoder architecture is unchanged, except that we additionally provide the decoder RNN cell with an indication of the target style, as mentioned in the previous section.
The attention mechanism allows the decoder to focus on (pay attention to) different parts of the input representation at different times. The point of using it here is that the input and output are different in how they represent time (the input is linear in time, the output is not, as we will see below), so the decoder needs a way to figure out where in the input to look as it generates the output sequence.
This is what the whole model looks like:
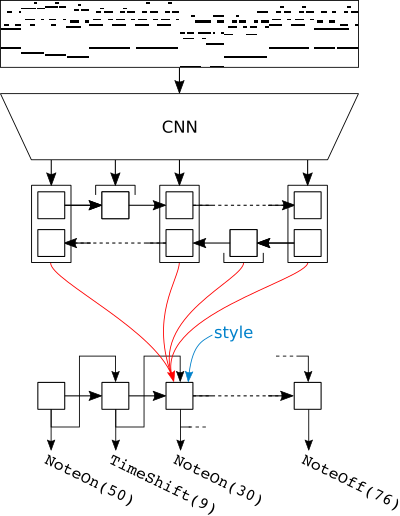
The ‘roll2seq’ architecture, consisting of a CNN-RNN encoder and an RNN decoder with attention. The attention mechanism is represented by the red arrows.
What still deserves an explanation is the output representation (shown at the bottom of the figure above).
In machine translation models, the output is a sequence of words or some kind of sub-word units.
In our case, we use a sequence of event tokens, based on those used by Magenta’s
PerformanceRNN.
To encode a piece of music in this way, we go through the piece from beginning to end and as we encounter note onsets and offsets, we emit NoteOn and NoteOff tokens (each with an associated pitch); between consecutive events, we emit TimeShift tokens, specifying the time difference (in terms of fractions of a beat).
This representation is very powerful, allowing to encode arbitrary polyphony while being easy to generate with an RNN decoder.
However, we also found that it’s prone to occasional timing errors, causing the model to ‘drift away’ from the beat.
To make the task easier, we trained a dedicated model for each output track (for the paper, we chose bass and piano). This way, the decoder doesn’t need to waste its capacity on keeping track of the different instruments playing at the same time, and can instead focus on the style of the track it was trained for. However, we found it helpful to provide multiple tracks of the original song as input to the encoder, since this gives the model more information about the song’s harmony.
Conclusion
The main advantage of using synthetic training data is that it enables supervised learning, and the quality of the learned transformation is then determined by the way the data was generated, which gives us a lot of control over the result. On the other hand, training exclusively on data generated by Band-in-a-Box means that the model will only be able to produce Band-in-a-Box-style outputs, which is definitely a limitation.
In any case, it’s interesting to see how far we can get with this method, and I’m curious whether unsupervised approaches (having access to a greater diversity of music data) will be able to surpass it. I also think synthetic data like ours can serve as a sort of sanity check for such unsupervised models since it should be easier to train on than ‘real-world’ music.
Check out the paper for more details on our approach, including how we evaluated our models. For people interested in playing around with our system, the code and the trained models are available for download.
References
-
Gino Brunner, Andres Konrad, Yuyi Wang, Roger Wattenhofer. “MIDI-VAE: modeling dynamics and instrumentation of music with applications to style transfer.” In Proceedings of the 19th International Society for Music Information Retrieval Conference (ISMIR), 2018. https://doi.org/10.5281/zenodo.1492525 ↩
-
Gino Brunner, Yuyi Wang, Roger Wattenhofer, Sumu Zhao. “Symbolic music genre transfer with CycleGAN.” In Proceedings of the 2018 IEEE 30th International Conference on Tools with Artificial Intelligence (ICTAI), 2018. https://doi.org/10.1109/ictai.2018.00123 ↩
-
Leon A. Gatys, Alexander S. Ecker, Matthias Bethge. “Image style transfer using convolutional neural networks.” In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2016. https://doi.org/10.1109/CVPR.2016.265 ↩
-
Noam Mor, Lior Wolf, Adam Polyak, Yaniv Taigman. “A universal music translation network.” ArXiv abs/1805.07848, 2018. ↩
-
Dzmitry Bahdanau, Kyunghyun Cho, Yoshua Bengio. “Neural machine translation by jointly learning to align and translate.” ArXiv abs/1409.0473, 2014. ↩