At the end of July, I attended the 3rd International Summer School on Deep Learning, DeepLearn 2019 in Warsaw, Poland. It offered a full week of exciting talks, courses, networking and pirogi eating. In total there were 22 courses to choose from, which covered several aspects of deep learning research ranging from introductory to advanced levels. All speakers were well-known experts in their respective areas of research. Beyond that, three keynote talks and many presentations by participants about their work gave further insight into the extremely wide range of research fields where deep learning is applied. In this post, I will address some lessons I learnt at the summer school and briefly summarize some of my favorite courses.
Deep Learning
While the basic concept of deep learning has been around for a long time, the techniques have not become widely adopted before this decade. The first formal neuron model was published already in 19431; convolutional neural networks2 and backpropagation3 were introduced in the 70s and 80s. However, due to the lack of computational power, training data and use cases at that time, the method did not attract the attention of the research community. This changed around 2012, when deep learning approaches started showing better performance than traditional machine learning methods on tasks such as speech recognition and image classification. This was possible due to the availability of GPUs for computation, more annotated data, and theoretical advances regarding activation functions and regularization. Nowadays, deep learning is successfully applied in many areas where previously domain knowledge was used to manually design features for other machine learning methods. Despite the outstanding performance of the deep learning approaches, they remain controversial due to the lack of explainability and the heuristics involved in the training process.
Andrew Ng once said that deep learning will change the world like electricity has changed the world in the beginning of the 20th century. I personally can imagine that, especially after I have seen the capabilities of the latest generative models in Warsaw. They can, for example, generate high quality photorealistic images of people or places that do not exist. Nobody would have believed that a few years ago. While being very powerful and having the potential to solve many problems, this also comes with the risk of misuse. In the future, it will become harder for us to differentiate between reality and fake. I find it therefore even more important to study deep learning and to understand its capabilities and limitations. Those risks were not directly addressed at the summer school, but there were talks about adversarial attacks and explainable machine learning dealing with security issues of deep learning.
Representation learning in limited data settings
This course by Gaël Varoquaux addressed the issue of not having enough training and test data available to learn a highly complex mapping with a Deep Neural Network (DNN) and to verify its performance with high statistical confidence. For example, most layers of a DNN for a classification task learn a representation of the input data while only at the very last layer(s) a decision is taken. When having limited data, it is advantageous to learn simpler representations and thereby restricting the class of functions that can be learned to map from the input space to the correct label. An illustrative example is shown in Figure 1.
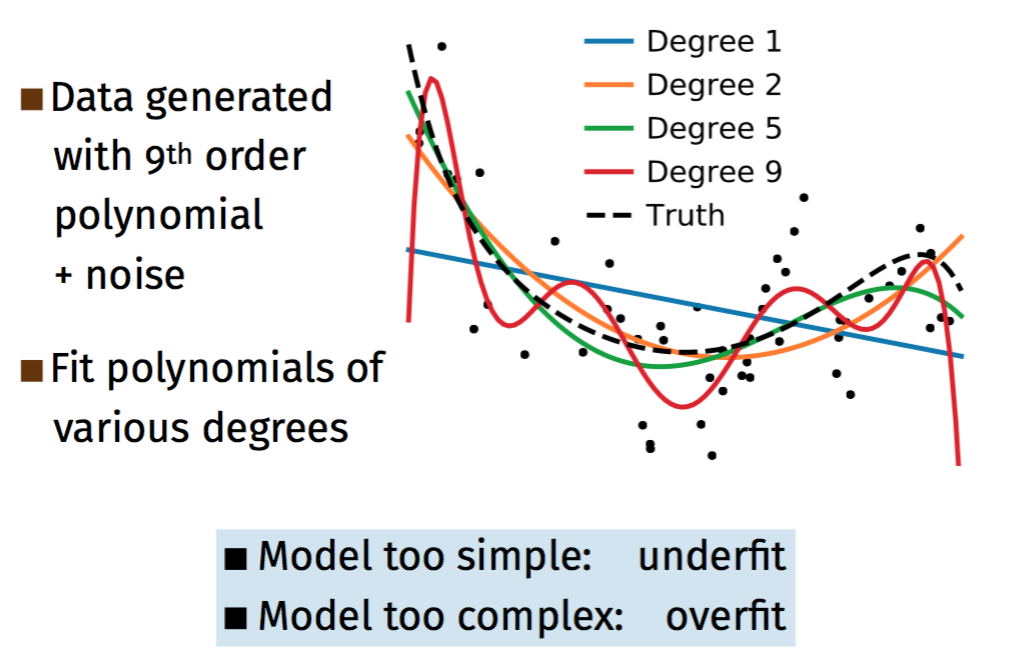
Figure 1: Simple vs. complex representations in a limited data setting. Figure by G. Varoquaux, usage with permission
The black dots represent a limited number of data points generated by a 9th order polynomial. However, this does not mean that a 9th order polynomial also describes the given data best. We see that a much simpler function, the 2nd order polynomial, actually describes the observed data better, while higher order polynomials tend to overfit.
It is crucial to choose the right representation method with respect to the available data. With good representations, this is keeping predictive information and losing nuisances, even linear prediction models can perform very well. As possible representations, he mentioned wavelets and models trained on more data for a related task (with the last layer(s) removed). Furthermore, independent component analysis and several variants of matrix factorization for unsupervised representation learning were introduced to learn simple representations. He showed that representations can be learned with these methods which are similar to representations Convolutional Neural Networks (CNNs) learn for image classification on much more data. The course finished with an introduction to Fisher kernels for representation learning. The main message was that due to limited data we often cannot use the full expressive power of very deep architectures and simple representations can lead to better performance in this case. The slides of the talk are available here.
Probabilistic deep learning for computer vision
In this course, Qiang Ji first highlighted some limitations of conventional DNNs. Training them is time consuming and often involves heuristics for hyperparameter tuning. After training, the models are deterministic, this is one fixed set of learned parameters is used to perform predictions on unseen data. This can lead to overfitting and does not allow the model to quantify the prediction uncertainty. He then introduced probabilistic deep learning techniques, which can overcome these limitations but also come with some drawbacks.
Probabilistic DNNs (PDNNs) estimate the parameters of the probability distribution of the outputs. The best model parameters are obtained by maximum likelihood estimation. While PDNNs can quantify the data uncertainty, they cannot quantify the model uncertainty. Another extension is the concept of Bayesian DNNs (BDNNs), which can capture also the model uncertainty. They do not estimate model parameters but construct their posterior distributions, which is used for predictions. In other words, no traditional learning is necessary: the model is rather constructed given observed data. This is a very powerful approach due to its generalization capabilities. However, empirical and full Bayesian inference require the computation of expectation over the model parameters, which becomes intractable for the usually high number of parameters. Approximations with Monte Carlo or variational methods have to be used in practice. The course finished with an introduction to Deep Probabilistic Graphical Models, which, in theory, fully capture the input, output and model uncertainties. However, they suffer from intractable inference and hence cannot be applied in large scale yet. To conclude, there are still some theoretical challenges to overcome for probabilistic deep learning but the models have a great potential for many applications.
Speech recognition and machine translation: from statistical decision theory to machine learning and deep neural networks
In his lectures, Hermann Ney reviewed about 40 years of speech recognition and machine translation research. He showed that the recently very successfully applied DNNs form part of the probabilistic approach to these tasks. His main message was that there has been a life before deep learning, where key concepts like Bayes decision rule, Gaussian modeling, Hidden Markov Models, or discriminative training were used. DNNs helped improving performance in speech recognition and machine translation drastically, but there will also be a life after deep learning, he emphasized. I appreciate this global view he gave on the topic.
Explainable artificial intelligence
Deep learning based models optimize mappings from an input to an output space without considering the interpretability of solution by humans. It is nonetheless often important to understand how the model came to a certain output, for example in medical or forensic applications. Sargur Srihari introduced concepts of explainable artificial intelligence. In general, we can differentiate between ante-hoc systems, where explainability is incorporated in a model from the beginning, and post-hoc explainability, where a blackbox model is explained by investigations after training. Ante-hoc explainability requires changes to the model architecture, so that the output can directly be accompanied by an explanation, e.g. “This is a Downy Woodpecker because it is a black and white bird with a red spot in its crown” for a bird classification task. This is convenient but potentially affects the model performance negatively. Post-hoc explainability may be harder to obtain but does not affect a model’s performance. One way to get post-hoc explanations, that has been mentioned in several courses of the summer school, is Local Interpretable Model-Agnostic Explanations (LIME)4. This method systematically manipulates inputs to a model and analyzes how the output changes.
![]()
Conclusion
The summer school was helpful in order to understand the current state of deep learning and the remaining challenges. There were much more interesting courses than I could attend or summarize here. Aaron Courville talked about deep generative models, Björn Schuller about intelligent signal processing, and René Vidal about the mathematics of deep learning, to name just a few. One aspect that could be improved was the size of the summer school with more than 1000 participants, which made interaction with the speakers quite hard even though three sessions ran in parallel. I could nevertheless improve my understanding of deep learning a lot and also got valuable hints for my own research through discussions with other participants or presenters. In general, the summer school was an enriching experience, which I can absolutely recommend, especially for first year PhD students.
Header image by Jimmy Moon on Unsplash
References
-
W. McCulloch, W. Pitts: A logical calculus of the ideas immanent in nervous activity. In: Bulletin of Mathematical Biophysics, Bd. 5: 115–133, 1943 ↩
-
K. Fukushima. Neocognitron: A self-organizing neural network model for a mechanism of pattern recognition unaffected by shift in position. Biological Cybernetics, 36(4): 93-202, 1980. ↩
-
D. E. Rumelhart, G. E. Hinton, R. J. Williams: Learning internal representations by error propagation. California Univ. San Diego La Jolla Inst for Cognitive Science, 1985 ↩
-
M. T. Ribeiro, S. Singh, C. Guestrin: Model-agnostic interpretability of machine learning. arXiv preprint arXiv:1606.05386, 2016. ↩